
North Mini Code
Cohere's open-source 30B/3B MoE coding model with 256K context, interleaved thinking, and strong SWE-Bench scores — all under Apache 2.0.
Updated 2026-06-15
Overview
North Mini Code 1.0 is Cohere's first open-weights model built specifically for coding, released on June 9, 2026. It's a sparse Mixture-of-Experts (MoE) architecture with 30 billion total parameters but only 3 billion active per token — 128 experts with 8 activated at inference time. That MoE design is the core trick: you get performance that punches well above the 3B active-parameter weight class while keeping inference costs and hardware requirements dramatically lower than a dense 30B model.
The model is purpose-built for agentic software engineering workflows. It supports interleaved thinking — reasoning steps interspersed with tool calls — so it can plan a multi-file code change, execute terminal commands, inspect results, and iterate. On SWE-Bench Verified it scores 67.6% (resolved) and on SWE-Bench Pro it hits 40.2%, putting it in competitive range with models several times its active parameter count. The 256K token context window is large enough to hold substantial codebases in a single pass, and it can generate up to 64K tokens of output.
The Apache 2.0 license makes this genuinely interesting for teams that want to self-host a capable coding agent. You can run it via vLLM, SGLang, Ollama, or Docker, and 26 quantized variants are available for running on consumer hardware. The tradeoff is clear: this is a code-specialist model, not a general-purpose assistant. It won't write your marketing copy or summarize your meeting notes — it's laser-focused on code generation, terminal tasks, and agentic SWE workflows. For that specific use case, it's one of the strongest open-source options available.
What sets North Mini Code apart
- Sparse MoE architecture: 30B total parameters, only 3B active per token
- Apache 2.0 license with 26 quantized variants for running on consumer hardware
- 256K context window with 64K max output for large codebases
- Interleaved thinking with native tool use built for agentic SWE workflows
Key features
Agentic Coding
Designed for autonomous software engineering workflows. Handles multi-step coding tasks — editing files, running commands, inspecting results, and iterating — using a SWE-Agent-style harness with tool-calling capabilities.
256K Context Window
Supports up to 256K tokens of context with 64K max output, allowing ingestion of large codebases, long file chains, and extended multi-turn agent sessions without truncation.
Interleaved Thinking
Generates explicit reasoning content alongside tool calls. The model thinks through its approach step-by-step before and between actions, improving reliability on complex multi-step tasks.
Tool Use
Native support for function calling via JSON schema. Works with bash, file editing, and custom tools — designed to operate within agentic frameworks like SWE-Agent and ReAct harnesses.
Pricing
Free tier: Completely free and open-source under Apache 2.0. You pay only for your own compute or LLM API hosting costs.
| Plan | Price | What's included |
|---|---|---|
| Open Source | Free | Full model weights under Apache 2.0 — self-host via vLLM, SGLang, Ollama, or Docker. 26 quantized variants available. |
Full model weights under Apache 2.0 — self-host via vLLM, SGLang, Ollama, or Docker. 26 quantized variants available.
Pros & cons
Pros
- ✓Strong SWE-Bench scores (67.6% Verified, 40.2% Pro) from only 3B active parameters — exceptional efficiency
- ✓Apache 2.0 license with 26 quantized variants makes self-hosting on consumer hardware viable
- ✓256K context window with 64K output handles large codebases in a single pass
- ✓Interleaved thinking with native tool use is purpose-built for agentic coding workflows
Cons
- ×Code-specialist only — not a general-purpose model, so don't expect strong performance on non-coding tasks
- ×Requires your own GPU infrastructure or API hosting — no managed cloud endpoint from Cohere yet
- ×Relatively new (June 2026) with limited third-party evaluations beyond the team's own benchmarks
- ×MoE architecture needs compatible serving infrastructure (vLLM, SGLang) — not a simple drop-in for all frameworks
How it compares
| Tool | Best for | Pricing | Score |
|---|---|---|---|
| North Mini Code | Developers building self-hosted agentic coding assistants who want a code-specialist open-weights model rather than a general-purpose LLM. | Free (open-source, Apache 2.0) | 8.2/10 |
| Cursor vs Cursor → | Professional developers handling complex, multi-file refactors who want AI built into a familiar VS Code-based editor. | Freemium | 9.5/10 |
| GPT-5.5 vs GPT-5.5 → | Developers and teams needing a frontier reasoning model for agentic coding workflows and large-codebase context handling. | API: $5/$30 per 1M tokens (in/out). ChatGPT Plus $20/mo, Pro $200/mo | 9.4/10 |
| Windsurf | Developers who want an AI IDE that autonomously plans, codes, tests, and iterates across a project with minimal input. | Freemium | 9.1/10 |



Compare head-to-head
Related reading

GLM-5.2: Z.ai Open Model Tops Coding Benchmarks
Z.ai's GLM-5.2 open-weights model beats GPT-5.5 on long-horizon coding benchmarks at a fraction of the cost, per VentureBeat.

Cohere North Mini Code: Open Agentic Coding Model
Cohere's North Mini Code packs 30B params into 3B active via 128-expert MoE, targeting agentic coding with Apache 2.0 weights.
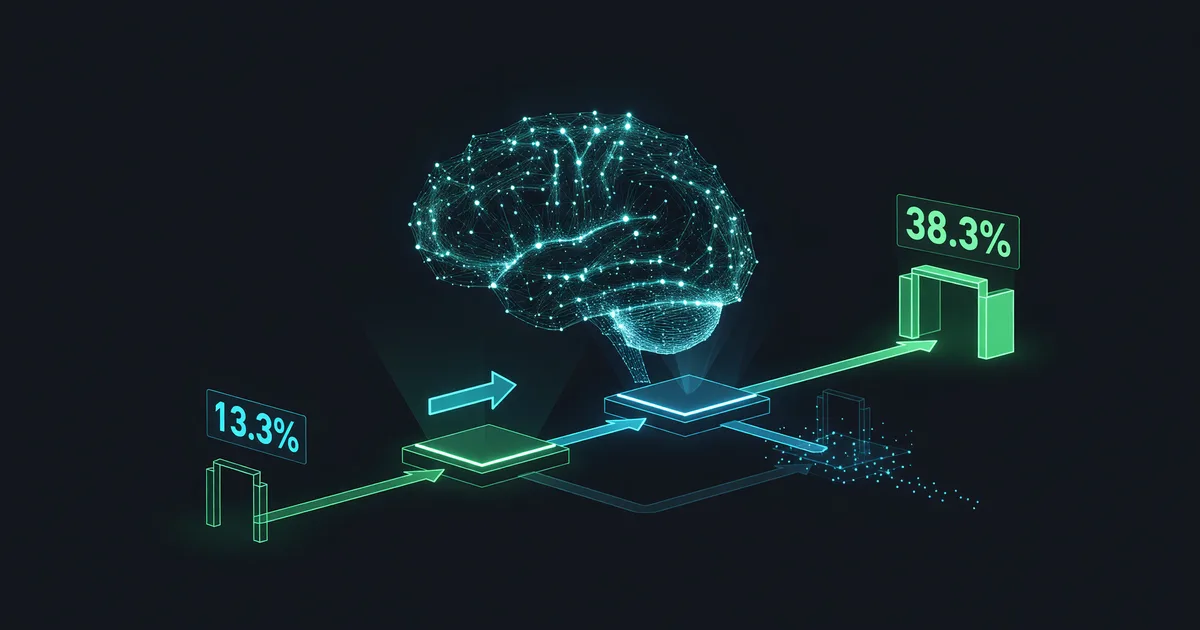
Two Settings Tripled GPT-5.6 Sol's ARC-AGI-3 Score
OpenAI says two Responses API settings took GPT-5.6 Sol from 13.3% to 38.3% on ARC-AGI-3's public set. Where that number holds, and where it doesn't.
Ready to try North Mini Code?
Head to the official site to start with North Mini Code — pricing and plans are listed above.
Visit North Mini Code